Nejnovější:
- Sailfish OS and memory
- Hillshade tile server
- Statistics of OSM Scout for Sailfish OS
- Nebezpečný router
- Tree model with Silica components
Podle data:
- listopad 2021
- leden 2019
- prosinec 2017
- prosinec 2016
- květen 2014
- duben 2014
- listopad 2013
- duben 2013
- duben 2011
- únor 2011
- leden 2011
- srpen 2010
- květen 2010
- březen 2010
- leden 2010
- říjen 2009
- duben 2009
- únor 2009
- říjen 2008
- září 2008
- srpen 2008
- duben 2008
- březen 2008
- únor 2008
Téma:
ReactConf 2014
Začátkem dubna jsem se s dvěma dalšími kolegy účastnil prvního ročníku React konference pořádané v Londýně. Byla to konference spíše komorní, účastníků bylo zhruba 300, přednášejích bylo pouze dvanáct. Byli mezi nimi lidé jako Jonas Bonér (CTO společnosti Typesafe, která stojí za programovacím jazykem Scala), Joe Armstrong (tvůrce jazyka Erlang), Ben Christensen (vývojář z Netflixu)…
Jak název napovídá, konference byla o reaktivním programování a reaktivních systémech obecně. Před konferencí jsem vůbec neměl představu co si pod tímto spojením představit. Základní myšlenky kterým by měl odpovídat „reaktivní“ systém jsou sepsány v reactive manifestu.
- řízen událostmi (event driven) – což umožňuje snadné rozšiřování, protokolem definovanou interakci komponent a přirozené asynchronní zpracování které usnadňuje paralelní zpracování.
- škálovaltelný – to znamená že větší zátež je možné zvládnout pouhým přidáním výkonu či výpočetních uzlů.
- odolný (resilient) – nefunkčnost jedné součásti systému (komponenty, datacentra) by neměla ohrozit funkčnost systému jako celku.
- responsivní – Aplikace by měly na akce uživatele reagovat okamžitě, nebo alespoň vyvolávat zdání že se tak děje. V dnešní době jsou lidé zvyklí pracovat s aplikacemi které poskytují výstupy v reálném čase.
První dva dny probíhaly přednášky. Zaznělo na nich spousta užitečných tipů a rad. Na YouTube kanálu konference jsou k dispozici záznamy.
Ve středu pak proběhly tři paralelní celodenní workshopy, každý hruba pro 20 lidí. Já jsem si vybral „<nobr>Lock-free</nobr> and <nobr>High-Performance</nobr> Concurrent Algorithms“ s Martinem Thompsonem. Tento workshop byl pro mě osobně na celé konferenci nejpřínosnější. Zopakoval jsem si detaily architektury x86, pochopil jaké mají různé vrstvy a komponenty vliv na výkon při programování paralelních aplikací a doplnil jsem si znalosti Java memory modelu. Na stejné téma měl Martin loni přednášku na QCon v San Franciscu, ovšem bez praktických příkladů…
I když se přikláním k názoru že „normální“ programátor by něměl psát paralelní algoritmy, myslím si že by o jejich základech měl mít povědomí. Paměťový model a architektura počítače se navíc netýká pouze synchronizace paralelních algoritmů ale i výkonu obecně. Proto jsem se rozhodl sepsat tento zápisek – snad bude ostatním prospěšný. Vycházel jsme ze svých poznámek z Thompsonova workshopu, materiálů k předmětu X36APS (Architektury počítačových systémů; FEL, ČVUT) a knihy Ulricha Dreppera – What Every Programmer Should Know About Memory.
Organizace paměti x86
V dnešní době se již téměř nesetkáme s jednojádrovým x86 procesorem. Dnešní procesory běžně obsahují více jak čtyři výpočetní jádra, některé architektury dokáží v jednom jádře vykonávat dvě vlákna paralelně (hyper-threading), navíc lze v jednom počítači mít zapojených více fyzických procesorů. Dřive byl řadič paměti (MC) umístěn v severním můstku (north bridge) a procesory byly k němu připojeny přes sběrnici FSB (Front-side bus). Dnes mají procesory řadič paměti integrovaný v sobě a paměťové moduly jsou k nim připojeny přímo. Pro rychlejší čtení dat z paměti (a zápisu do paměti) obsahují procesorová jádra několik (dnes tři) úrovně keší. Jednotlivé procesory jsou propojeny sběrnicí QPI (Quick Path Interconnect) která protokolem MESI (F) zajišťuje koherenci paměťových keší. Pro běžící vlákna je celá paměťová hierarchie včetně keší transparentní a paměťový prostor se pro ně jeví jako spojitý. Jediným pozorovatelným důsledek této složité hierarchie jsou latence přístupu k datům v různých vrstvách. Obecně platí že vlákna by měla přistupovat k datům která jsou v paměti blízko u sebe (pole vs. hash mapa) a co nejméně dat sdílet s ostatními vlákny. Je výhodnější data zkopírovat pro každé vlákno (paměť je levná, propustnost velká), než přistupovat ke stejným datům z více vláken (velká latence při práci s nelokálními daty). Sdílení dat se ale nelze vyhnout vždy…
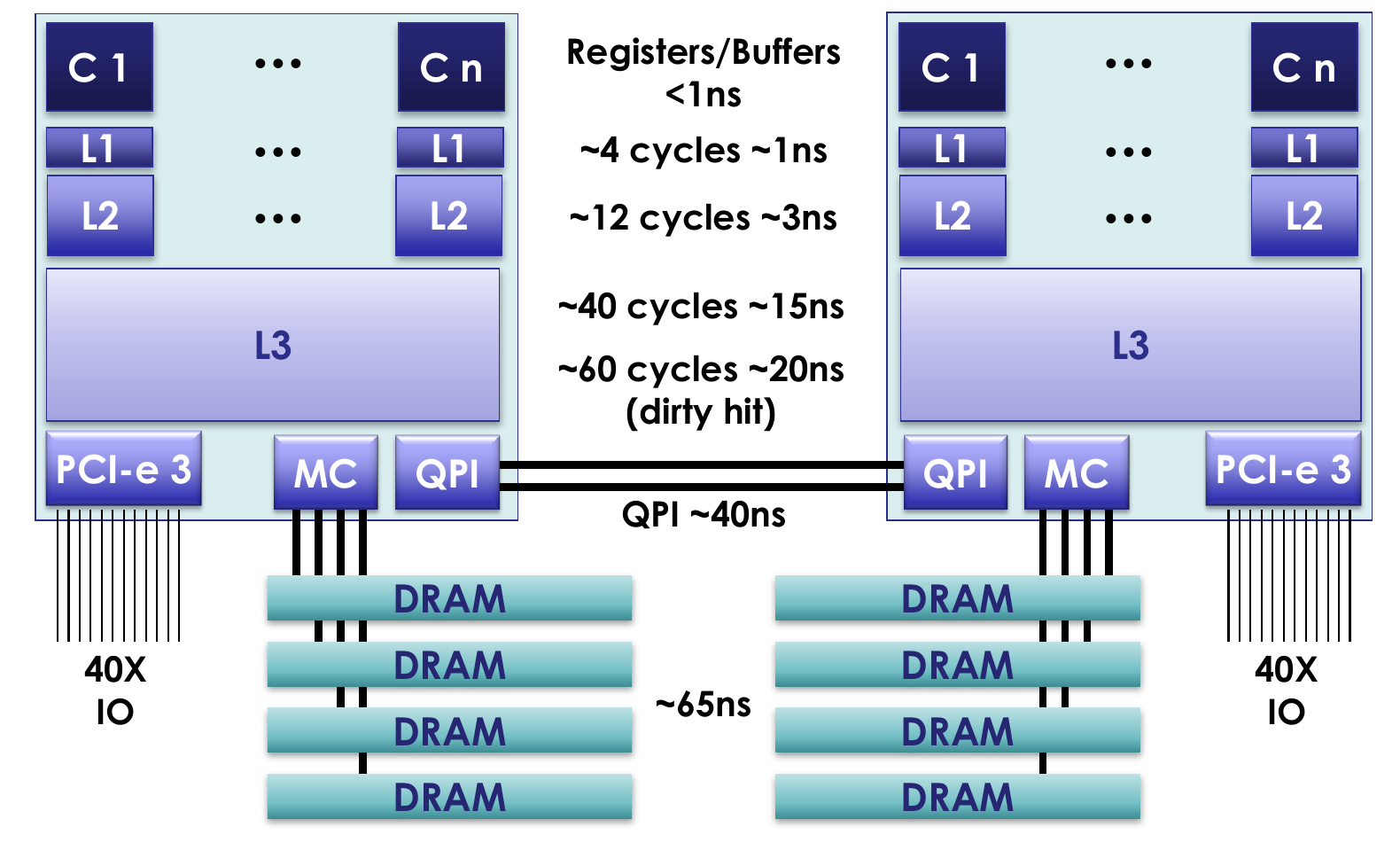
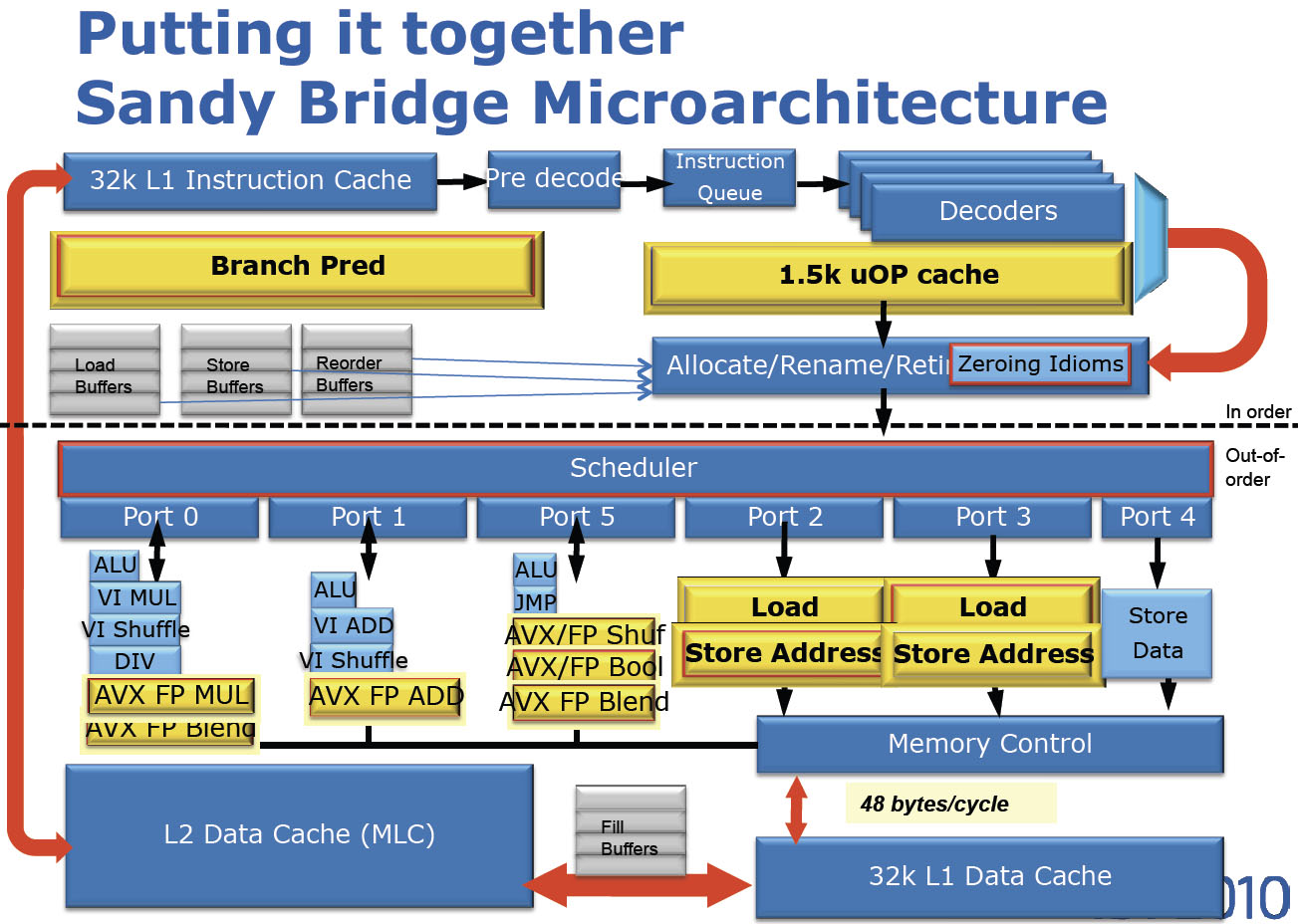
Procesor vykonává instrukce každého vlákna v přesně daném pořadí. Tedy alespoň to tak musí při pohledu zvenku vypadat. Reálně ale procesor ve své pipeline zpracovává několik instrukcí naráz v tzv. slotech. Pipeline má několi fází, například dekódování instrukce, načítání operandů (z paměti do registrů), vlastní zpracování a zápis výsledku. Instrukce mohou být zpracovávány v libovolném pořadí, za předpokladu že výsledné hodnoty odpovídají zpracování instrukci po instrukci. Kompilátor programu (běhové prostředí Javy) nemusí navíc výsledek ukládat ihned do paměti, ale může jej po libovoně dlouhou dobu uchovat v registrech. Při zápisu do paměti navíc není hodnota zapsána ihned do transparentní L1 cache, je ale umístěna do Memory Order buffer (MOB). Samotný zápis může být tedy o mnoho cyklů opožděn. Pokud jiná vlákna (jádra) v tomto mezičase proměnnou z paměti načtou, uvidí starou hodnotu. To ale samozřejmě neplatí při použití některých ze synchronizačních mechanizmů.
Jaké tento opožděný zápis může mít důsledky v praxi si můžeme vyzkoušet na následujícím příkladu. Dvě vlákna běžící paralelně přičítají sdílenou proměnnou, každé 100 000 000 x. Kdybychom příklad spustili na jednojádrovém procesoru, výsledek by byl 200 000 000 (téměř vždy), na systému s více jádry nám program bude vypisovat hodnotu mezi 100 a 200 miliony.
public class MemoryTest {
static int variable = 0;
static int ITERATIONS = 100 * 1000 * 1000;
static class Adder implements Runnable{
@Override
public void run() {
for (int i = 0; i < ITERATIONS; i++){
variable ++;
}
}
}
public static void test() throws InterruptedException {
Thread t1 = new Thread(new Adder(), "one");
Thread t2 = new Thread(new Adder(), "two");
long startTime = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("normal variable = " + variable);
System.out.println("duration: "+ ((System.nanoTime() - startTime) / 1000000) + " ms");
}
public static void main(String[] args) throws InterruptedException {
while(true){
test();
Thread.sleep(10000);
}
}
}
x86 memory model
Proto je při přístupu k jedné proměnné z více vkláken potřeba tato vlákna synchronizovat, nebo používat používat podmíněný zápis (označovaný jako compare and swap). Architektura x86 nám po hardwarové stránce zaručuje tyto podmínky [1] [2]:
- Pořadí čtení je zachováno. (Loads are not reordered with other loads.)
- Pořadí ukládání je zachováno. (Stores are not reordered with other stores.)
- Pořadí zápisu a čtení je zachováno. (Stores are not reordered with older loads.)
- Zápisy mohou být přeskupeny se čteními pokud směřují na jinou adresu. (Loads may be reordered with older stores to different locations but not with older stores to the same location.)
- Na víceprocesorovém systému pořadí operací může být libovolné. [In a multiprocessor system, memory ordering obeys causality (memory ordering respects transitive visibility)].
- Na víceprocesorovém systému je při zápisu na stejné místo dodržováno absolutní pořadí. (In a multiprocessor system, stores to the same location have a total order.)
- Na víceprocesorovém systému mají instrukce zámku absolutní pořadí. (In a multiprocessor system, locked instructions have a total order.)
- Pořadí čtení a zápisů s instrukcemi zámku je zachováno. (Loads and stores are not reordered with locked instructions.)
Java memory model
Memory model mohou mít různé počítačové architektury odlišný. Při psaní aplikací v jazyku C ve starším standardu jak C11 musí programátor tato pravidla cílové architektury a použitého kompilátoru znát. To značně komplikuje přenositelnost (především vícevláknových) programů napsaných v C.
Java má naštěstí memory model definovaný přímo v jazyce (od Java 5, JSR-133) a je tedy nezávislý na platformě, což umožňuje snadnou přenositelnost programů. Ve zkratce, model definuje kdy jsou provedené změny viditelné pro ostatní vlákna (Visibility of change in the correct order is key). Zaručuje následující:
- V rámci jednoho vlákna je pořadí viditelnosti změn zachováno. (“within-thread-as-if-serial” for program order)
- Pořadí operací je zachováno se zámky a přístupy k volatilním
proměnným. („happens-before” clarification on program order for locks
and volatile variables)
- Release before acquire of a lock
- Write of a volatile field before the read to fix store order
- Final proměnné musejí být viditelné po zkončení konstruktoru. („initialisation safety” final fields must be visible at the end of a constructor)
- Čtení i zápis volatilních proměnných je atomické, včetně 64 bitových typů. (Fields declared volatile are read and written as atomic operations even when double and long)
Co přesně znamená volatile
Proměnné označené klíčovým slovem volatile se v mnohém
chovají jinak než standardní proměnné. Sémantika volatile
byla v Javě 5 rozšířena, následující body tedy nemusí platit pro
starší JVM.
- Čtení i zápis je atomický, včetně 64 bitových
hodnot (double, long) na 32 bitových platformách (JVM). Při zápisu hodnoty
do
longproměnné se tedy nemůže stát že by jiné vlákno načetlo hodnotu kde horních 32 bitů je již aktualizovaných a spodních 32 obsahuje stále starou hodnotu. Toho je na x86_32 dosaženo použitím MMX registrů. - Pořadí zápisu volatile a ostatních proměnných je zachováno. To znamená že v okamžiku kdy je pro ostatní vlákna vidilná změna volatile proměnné jsou vidilelné i všechny ostatní změny provedené tímto vláknem před touto změnou. Na x86 to znamená že zápis je proveden s vyprázdněním MOB a čtení je vždy realizováno z L1 cache (i kdyby proměnná byla již v registru). Díky tomu je práce s volatile proměnnými poněkud pomalejší.
- Konstruktor je vždy dokončen před přiřazením reference do
proměnné. Tato vlastnost
volatileproměných je málo známa, přesto je klíčová pro správnou funkci <nobr>double-check</nobr> patternu.private final Object lock = new Object(); private volatile SomeObject singleton = null; public SomeObject getSomeObject(){ if (singleton == null) { synchronized(lock) { if (singleton == null) { singleton = new SomeObject(); } } } return singleton }
Pokud by singleton nebyl označen jako volatile, JIT compiler by měl volné ruce v optimalizacích a mohl by tak nejdříve alokovat nový SomeObject, přiřadit referenci do proměnné a až poté vykonat kód konstruktoru. Jiná vlákna by mohla přečíst nenulovou hodnotu a pracovat s neinicializovaným objektem. Podrobně je tento problém popsán zde.
Třídy Atomic* (java.util.concurrent.atomic)
Atomické reference z balíku java.util.concurrent.atomic
nejsou součástí memory modelu, pro čtení a zápis ale zaručují stejné
chování jako volatile proměnné. Navíc mají možnost podmíněného
zápisu, přístupného metodou compareAndSet. Pokud není nutné
zachovat pořadí s ostatními instrukcemi, lze pro nastavení použít
lazySet, případně weakCompareAndSet. Při jejich
použití může JIT kompiler provádět více optimalizací a výsledný kód
tak může být rychlejší.